


Background
Albert Einstein once proclaimed that “compound interest is the eighth wonder of the world” (allegedly, at least; people attribute all kinds of sayings to that guy). Let’s just assume that he did. This is the single most important reason why people participate in the markets. The magic of compounding interest turns time into an exponential money multiplier, and the greater the rate the more dramatic the results. This is the single most important concept that traders need to understand.
In order to obtain true wealth in the financial markets, one must scale up the size of their positions as their account grows. A sharpe ratio of 10 is meaningless if it’s achieved trading a handful of shares back and forth. The question is: how much? What percentage of one’s finite capital should they risk on each trading opportunity? Is absolute return on investment the only thing that matters, or must one consider the path to the end? This series of posts will attempt to answer these questions in a way traders (without a PhD) can easily understand. This first post will establish some basic foundations which we will build on to develop a position sizing strategy that traders can implement.
The Jupyter notebook to follow along with this post can be found here. Before starting, it should be noted that Ralph Vince has written fantastic books on this topic and the following posts draw inspiration from his work. I highly recommend that everyone read them for a more thorough understanding of the underlying mathematics.
Basic Example: Weighted Coin Flip
Let’s start with an illustrative example. I am a wealthy (and extremely generous) casino owner and I’ve offered you the following opportunity: I’m going to flip a fair coin, and let you gamble on the results. If it comes up heads, I’ll double whatever you bet; tails, you lose your whole wager. It should be immediately obvious this is a game you want to play. The question, then, is how much of your net worth should you put at stake? Intuitively, it should be less than 100%.. you’re broke the first time a flip comes up tails!
Before answering “how much?”, we’ll address the concept of expected value. Traditionally, this is expressed as the mean of all possible outcomes:
![\displaystyle \mathbf{E}[X] = \frac{1}{n}\sum_{i=1}^{n} x_{i}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbf%7BE%7D%5BX%5D+%3D+%5Cfrac%7B1%7D%7Bn%7D%5Csum_%7Bi%3D1%7D%5E%7Bn%7D+x_%7Bi%7D&bg=ffffff&fg=000&s=0&c=20201002)
where:
X = a random variable representing all possible outcomes
n = the total number of outcomes
x = the value of each individual outcome
We’ll refer to this value as the arithmetic mean. This tells us that for each $1 wagered, we should earn (2 + -1) / 2 = $0.50 per flip. However, what we’re more interested in is the geometric expected value, the expected return on our capital per bet. The higher this number is, the faster our wealth will compound and the greater our final capital value will be. We’ll refer to this as the geometric holding period return (shortened to GHPR).This value can be determined using the following formula:
![\displaystyle GHPR = \Big[\prod_{i=1}^{n} (x_{i} + 1)\Big]^\frac{1}{n} - 1](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+GHPR+%3D+%5CBig%5B%5Cprod_%7Bi%3D1%7D%5E%7Bn%7D+%28x_%7Bi%7D+%2B+1%29%5CBig%5D%5E%5Cfrac%7B1%7D%7Bn%7D+-+1&bg=ffffff&fg=000&s=0&c=20201002)
In the coin flip example, this equates to (3 * 0) ^ (1/2) – 1 = -1. What this tells us is that if one risks 100% of their capital on each coin flip, the expected return is -100%; aka they lose all of their money. This makes sense, given that if played long enough the coin will eventually come up tails, causing instant bankruptcy.
Python Code:
def expected_arith(returns):
expected_arith = np.mean(returns)
return expected_arith
def expected_geom(returns):
returns = np.array(returns)
expected_geom = np.product(1 + returns) ** (1 / len(returns)) - 1
return expected_geom
coin_outcomes = np.array([2, -1])
coin_exp_arith = expected_arith(coin_outcomes)
coin_exp_geom = expected_geom(coin_outcomes)
print('Expected Value (Arithmetic): {}%'.format(coin_exp_arith * 100))
print('Expected Value (Geometric): {}%'.format(coin_exp_geom * 100))
Expected Value (Arithmetic): 50.0%
Expected Value (Geometric): -100.0%
Fractional Stake
Obviously, 100% of our bankroll was not the ideal stake. If we were instead to risk 1% of our capital on each flip, the potential outcomes would become a 2% gain or a 1% loss. Let’s examine the expected values of this scenario.
fractional_coin_outcomes = 0.01 * coin_outcomes
coin_exp_arith_fr = expected_arith(fractional_coin_outcomes)
coin_exp_geom_fr = expected_geom(fractional_coin_outcomes)
print('Expected Value (Arithmetic): {}%'.format(np.round(coin_exp_arith_fr * 100, 3)))
print('Expected Value (Geometric): {}%'.format(np.round(coin_exp_geom_fr * 100, 3)))
Expected Value (Arithmetic): 0.5%
Expected Value (Geometric): 0.489%
With a smaller fraction of our capital risked per flip, the GHPR is now positive (as expected, given such a positive wager). Also notice that the geometric expected value is smaller than the arithmetic value. Assuming multiple unique outcomes, this will always be the case; we won’t go into why. But 5% was just a guess! Surely there is a number between 1% and 100% that maximizes the growth of our capital without risk of going bust. A formula called the Kelly Criterion solves just this problem.
Kelly Criterion
The Kelly Criterion is well-known among gamblers as a way to decide how much to bet when the odds are in your favor. The version of the formula that addresses simple binary scenarios such as our contrived coin-flip example is defined as follows:
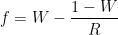
where:
f is the optimal fraction of our capital to stake on each bet
W = the probability of winning a given bet
R = the ratio of a winning outcome to a losing outcome
Let’s see what the optimal fraction based on the Kelly Criterion is.
def kelly_fraction(returns):
returns = np.array(returns)
wins = returns[returns > 0]
losses = returns[returns <= 0]
W = len(wins) / len(returns)
R = np.mean(wins) / np.abs(np.mean(losses))
kelly_f = W - ( (1 - W) / R )
return kelly_f
def kelly_results(returns):
bounded_rets = bound_returns(returns)
kelly_f = kelly_fraction(bounded_rets) / worst_loss(returns)
exp_arith_kelly = expected_arith(bounded_rets * kelly_f)
exp_geom_kelly = expected_geom(bounded_rets * kelly_f)
print('Kelly f: {}'.format(np.round(kelly_f, 3)))
print('Expected Value (Arithmetic): {}%'.format(np.round(exp_arith_kelly * 100, 5)))
print('Expected Value (Geometric): {}%'.format(np.round(exp_geom_kelly * 100, 5)))
kelly_results(coin_outcomes)
Kelly f: 0.25
Expected Value (Arithmetic): 12.5%
Expected Value (Geometric): 6.06602%
Optimal f
Alternatively, we can see if there’s a sweet spot for stake percentage by iterating through all possible fractions and evaluating the GHPR value at each. This will generate a curve, and the peak of this curve represents the optimal fraction to bet. Ralph Vince has termed this value “optimal f”. We’ll consider all values which don’t cause us to go bust. To do so, we must divide the stake percentage by our worst loss: the most we would ever wager is an amount that would bankrupt us should the worst possible outcome be realized.
def worst_loss(returns):
return np.abs(np.min(returns))
def bound_returns(returns):
return returns / worst_loss(returns)
def get_f(returns):
exp_df = pd.DataFrame(columns=['arithmetic', 'geometric'])
f_values = np.linspace(0, 1, 101)
max_loss = worst_loss(returns)
bounded_f = f_values / max_loss
for f in bounded_f:
exp_df.loc[f, 'arithmetic'] = expected_arith(f * returns)
exp_df.loc[f, 'geometric'] = expected_geom(f * returns)
optimal_f = exp_df['geometric'].idxmax()
return {'f_curve':exp_df, 'optimal_f':optimal_f, 'max_loss':max_loss}
def f_plots(f, title=''):
f_curve = f['f_curve']
optimal_f = f['optimal_f']
max_loss = f['max_loss']
f_exp = f_curve.loc[optimal_f, 'geometric']
fig, ax = plt.subplots(1, 1, figsize=(10, 10), sharex=False)
f_curve.plot(ax=ax)
ax.plot(optimal_f, f_curve.loc[optimal_f, 'geometric'], color='r', marker='x')
ax.axhline(0, color='k')
ax.axvline(optimal_f, color='r', linestyle=':')
ax.axhline(f_curve.loc[optimal_f, 'geometric'], color='r', linestyle=':')
ax.set_xlim(0, optimal_f * 2.25)
ax.set_ylim(-f_exp, f_exp * 1.25)
ax.set_xlabel('Fraction Staked')
ax.set_ylabel('Expected Return %')
ax.set_title(title + ' Optimal f')
plt.savefig(title + ' optimal f.png', bbox_inches='tight')
plt.show()
def f_results(f):
f_curve = f['f_curve']
optimal_f = f['optimal_f']
exp_arith = f_curve.loc[optimal_f, 'arithmetic']
exp_geom = f_curve.loc[optimal_f, 'geometric']
print('Optimal f: {}'.format(np.round(optimal_f, 3)))
print('Expected Value (Arithmetic): {}%'.format(np.round(exp_arith, 5) * 100))
print('Expected Value (Geometric): {}%'.format(np.round(exp_geom, 5) * 100))
coin_f = get_f(coin_outcomes)
f_plots(coin_f, title='Coin Flip')
f_results(coin_f)

Optimal f: 0.25
Expected Value (Arithmetic): 12.5%
Expected Value (Geometric): 6.066%
As we can see, this approach returns the same results as the Kelly formula. We’ll soon discover this approach offers some benefits to plugging values into the formula. It’s also important to notice from the graph the implications of risking too much with your capital. Even though this game has an extremely high expected payout (almost surely higher than any you’re likely to find in real life!), risking more than 50% of your total bankroll on each bet will cause the expected compound growth of your capital to be negative. In fact, staking more than the optimal f fraction of your account will actually have a negative impact on compounded growth. It should be clear that the idea of “betting big to win big” is only true to a point.
Next Example: Dice Roll
Let’s step things up a notch here. The next scenario we’ll consider is a dice roll. I’m still the same altruistic rich guy, and I’ve offered you the opportunity to bet on the roll of a six-sided die. If an even number comes up, I’ll pay you that multiple of your bet. If it comes up odd, you pay me that multiple. Again, we see that the arithmetic expectancy of this game is in your favor. However, in order to assess the geometric average return of this game, we’ll first need to bound the returns. Since you’ll pay me five times your wager if you roll a five, the most you could possibly bet is 1/5 of your capital.
dice_outcomes = np.array([-1, 2, -3, 4, -5, 6])
dice_outcomes_bounded = bound_returns(dice_outcomes)
dice_exp_arith = expected_arith(dice_outcomes_bounded) * 100
dice_exp_geom = expected_geom(dice_outcomes_bounded) * 100
print('Expected Value (Arithmetic): {}%'.format(np.round(dice_exp_arith), 3))
print('Expected Value (Geometric): {}%'.format(np.round(dice_exp_geom), 3))
Expected Value (Arithmetic): 10.0%
Expected Value (Geometric): -100.0%
Again, we see that what looks like a great bet at the onset will eventually leave you dead broke if you risk too much. We can use the Kelly Criterion to try and determine what the optimal amount to stake on each roll is.
kelly_results(dice_outcomes)
Kelly f: 0.025
Expected Value (Arithmetic): 1.25%
Expected Value (Geometric): 0.78728%
And let’s compare that to the optimal f value by evaluating the peak of the curve.
dice_f = get_f(dice_outcomes)
f_plots(dice_f, title='Dice Roll')
f_results(dice_f)

Optimal f: 0.034
Expected Value (Arithmetic): 1.7000000000000002%
Expected Value (Geometric): 0.844%
In the scenario where possible outcomes are not binary, the Kelly Criterion doesn’t return the optimal solution. You’d be leaving money on the table calculating your bet size this way!
Practical Example: Market Returns
Finally, we’ll get to a real application. No casino can stay in business offering games that give gamblers an edge over the house (if you find one, let me know!). However, the stock market is historically proven to be a reliable way to grow one’s capital through compounding . Let’s find out how much capital we should devote to the market in order to get the maximum returns!
It’s worth mentioning at this point that the approaches used going forward are only valid if future market returns match past returns. As any financial advisor worth their salt will tell you, this IS NOT GUARANTEED. Unlike the games covered previously, where all possible outcomes were defined in advance, the markets offer no guarantees. The best we can do is plug in past returns and make tweaks if we deem them necessary.
For this study, we’ll use the daily returns of the ‘SPY’ S&P 500 ETF as our outcomes. Let’s take a look at some summary stats:
# SPY.csv file available in GitHub 'data' folder
spy = pd.read_csv('SPY.csv', parse_dates=True, index_col=0)
spy.sort_index(ascending=True, inplace=True)
# Use daily returns from adjusted closing prices'
spy_returns = spy['Adj Close'].pct_change().dropna()
spy_returns.describe()
count 6357.000000
mean 0.000425
std 0.011575
min -0.098448
25% -0.004382
50% 0.000669
75% 0.005787
max 0.145198
Name: Adj Close, dtype: float64
Again, let’s compare the fraction suggested by the Kelly formula with optimal f.
kelly_results(spy_returns)
Kelly f: 0.568
Expected Value (Arithmetic): 0.02413%
Expected Value (Geometric): 0.02197%
spy_f = get_f(spy_returns)
f_plots(spy_f, title='SPY Returns')
f_results(spy_f)

Optimal f: 3.149
Expected Value (Arithmetic): 0.134%
Expected Value (Geometric): 0.067%
The fraction suggested by Kelly is actually far from optimal. In this case, we should actually bet more capital than we have. To do so, we’ll have to employ leverage; either by borrowing money to increase the bet size or by trading instruments with inherent leverage such as options or futures.
Drawdown
To this point, we’ve solely focused on maximizing the return on our capital. Investing at optimal f would have resulted in account value over 60 times greater than its starting value. However, as an investor we’re likely just as concerned with how much risk we’re taking on. We’ll see below that the path taken to reach the maximum final account value is certainly not an easy one. From peak equity, an investor would need to weather a 97% drawdown on the path to the greatest final account value! It’s unlikely that anyone could stick with this strategy.
def equity_curve(returns):
eq = (1 + returns).cumprod(axis=0)
# Set the starting value of every curve to 1
# normalized_eq = raw_eq / raw_eq[0]
return eq
def drawdown(equity_curve):
eq_series = pd.Series(equity_curve)
drawdown = eq_series / eq_series.cummax() - 1
return drawdown
def max_drawdown(equity_curve, percent=True):
abs_drawdown = np.abs(drawdown(equity_curve))
max_drawdown = np.max(abs_drawdown)
if percent == True:
return max_drawdown * 100
else:
return max_drawdown
def equity_plot(returns):
fig, ax = plt.subplots(2, 1, figsize = (10, 10), sharex=True)
eq = equity_curve(returns)
dd = drawdown(eq) * 100
ax[0].plot(eq)
ax[0].set_title('Equity (Multiple of Starting Value)')
dd.plot(ax=ax[1], kind='area')
ax[1].set_title('Drawdown (%)')
plt.show()
optimal_returns = spy_returns * spy_optimal_f
equity_plot(optimal_returns)
max_dd = max_drawdown(equity_curve(optimal_returns))
print("Max Drawdown: {}%".format(np.round(max_dd, 2)))

Max Drawdown: 97.23%
We’ll take a closer look at maximizing return with drawdown constraints in Part 2.
Conclusion
In a scenario with random outcomes and a positive mathematical expectancy, there is an optimal fraction of your finite capital to stake on each event. We’ve looked at two methods to determine this optimal fraction, the Kelly Criterion and optimal f. We’ve also seen that risking more than this optimal fraction does not reward a gambler/trader with any additional return. However, this optimal fraction also results in the maximum amount of drawdown on the way to its final account value.
Read Part 2: Dealing with Drawdown here
If you liked this article, leave a comment below and/or join the chat in the Quant Talk telegram group:
What? Optimal f is bounded between 0..1, how could you get 3.149, dude?
Ok, I got it, you have 2 errors in Jupyter.
I am staring into Ralph Vinces’s Portfolio mathematics for the last maybe 3 weeks. The correct formula for finding optimal f is:
TWR = product of (1 + f * (−returns/biggest loss))
In JS:
const biggestLoss = Math.min(…returns);
for (f = 0.01; f 1 + (f * (-return / biggestLoss)))
.reduce((product, item) => product * item, 1);
}
and f corresponding to highest TWR is optimal f.
Only then you can calculate geometric mean, which is a comparison value for comparing the profitability of your strategies.
Page 125 of mentioned book:
1. Take the trade listing of a given market system.
2. Find the optimal f , either by testing various f values from 0 to 1 or
through iteration. The optimal f is that which yields the highest TWR.
3. Once you have found f you can take the Nth root of that TWR corresponding to your f , where N is the total number of trades. This is your geometric mean for this market system. You can now use this geometric mean to make apples-to-apples comparisons with other market systems, as well as use the f to know how many contracts to trade for that particular market system.
What you did is finding optimal f based on highest geometric mean (which is calculated from TWR).
So you should do
for f in f_values:
exp_df.loc[f, ‘TWR’] = np.product(1 + f * (returns / max_loss))
optimal_f = exp_df[‘TWR’].idxmax()
I must admin your code in Python is neat and those charts are fabulous. I use pandas and pyplot just for backtesting analytics.
After reading plenty of Vince’s materials and reading a lot of forums, one has to add that neither Kelly nor Optimal f are suitable for real world trading, because the numbers produced are just insane.
In my (looks like after using optimal f fraction) best trading strategy has optimal f mostly = 0.980, in other words allocating 98% of your capital to a single position. Insane.
So one has to look at optimal f as the thing it actually stands for – maximum geometric growth as a means of further optimizing your money and risk management.
Excellent work though and looking forward to LSPM and a next part! This here with optimal f is were I ended so far with position sizing.
Oh, the JS code got scrambled by this blog.
nemozny,
Thanks for reading, glad you enjoyed the charts! As you’ve pointed out, the largest value for f in Ralph Vince’s calculations is 1. In this case, 1 represents the fraction where your worst loss will totally wipe you out. He achieves this by dividing f by the largest loss at each iteration. In order to convert this number to a practical fraction for calculating number of shares/contracts, you have to divide this value by the largest loss.
For instance, the largest daily loss in SPY is ~10%. So whatever value you achieve using Ralph’s method must be multiplied by 10 to get the real value you would invest. In my calculations, I divided all possible f values by the largest loss ahead of time, so that the final output would represent a more practical percentage of one’s total account.
Hope this makes sense.
Hi Brian. It makes a sort of sense.
I think we are mixing 2 things here, optimal f and optimal leverage.
1. optimal f – Is calculated as I said in my previous post, by finding highest corresponding TWR. But I think you did the calculation wrong by maximizing geometric average
optimal_f = exp_df[geometric].idxmax()
which is not the same. Geometric average is devised from TWR, not the other way.
2. optimal leverage – true, it is calculated from optimal_f divided by maximum loss. So taking your example 10% or 0.1 largest SPY loss, with f 0.31 = 0.31 / 0.1 = 3.1, so using 310% of your equity.
However I don’t see this calculation in your jupyter.
I think the greatest deal of confusion is with this “what is optimal f? A divisor of the biggest percieved loss between 0 and 1, that you will use in determining how many units to trade”. [Ralph Vince – The leverage space portfolio model]
Taking Ralph’s example – $50,000 account(stake) / $5000 biggest loss per contract / 0.5 optimal f = 5 contracts
However you don’t need this AWKWARD formula, taking just $50000 * optimal f 0.5 = $25,000 to bet/trade in one position. This $25,000 you can divide by whatever you want to buy.
This “divisor” thing is just for the “number of contracts” calculation, which is just ambiguous.
I have to admit, I haven’t read Ralph’s books in a few years so we might differ on a few details. That being said, the post was not meant to re-create his work, but rather to demonstrate the principles behind geometric expected return and find the optimal position size to maximize this value. With regards to finding TWR, maximizing GHPR will maxmixize TWR and vice versa.
The calculation to divide by the largest loss is written in the (get_f) function as “bounded_f = f_values / max_loss”. This way, the potential leverage is bounded by the size that would cause you to blow up, and the space is divided up evenly. This isn’t “by the book” as Ralph Vince does it so to speak, but accomplishes the same goal in a way that’s easier for me to understand. I also find it easier to keep track of percentage returns than dollar per contract returns.
All right, I respect that. Thanks for your work anyway! Looking forward to part 2.